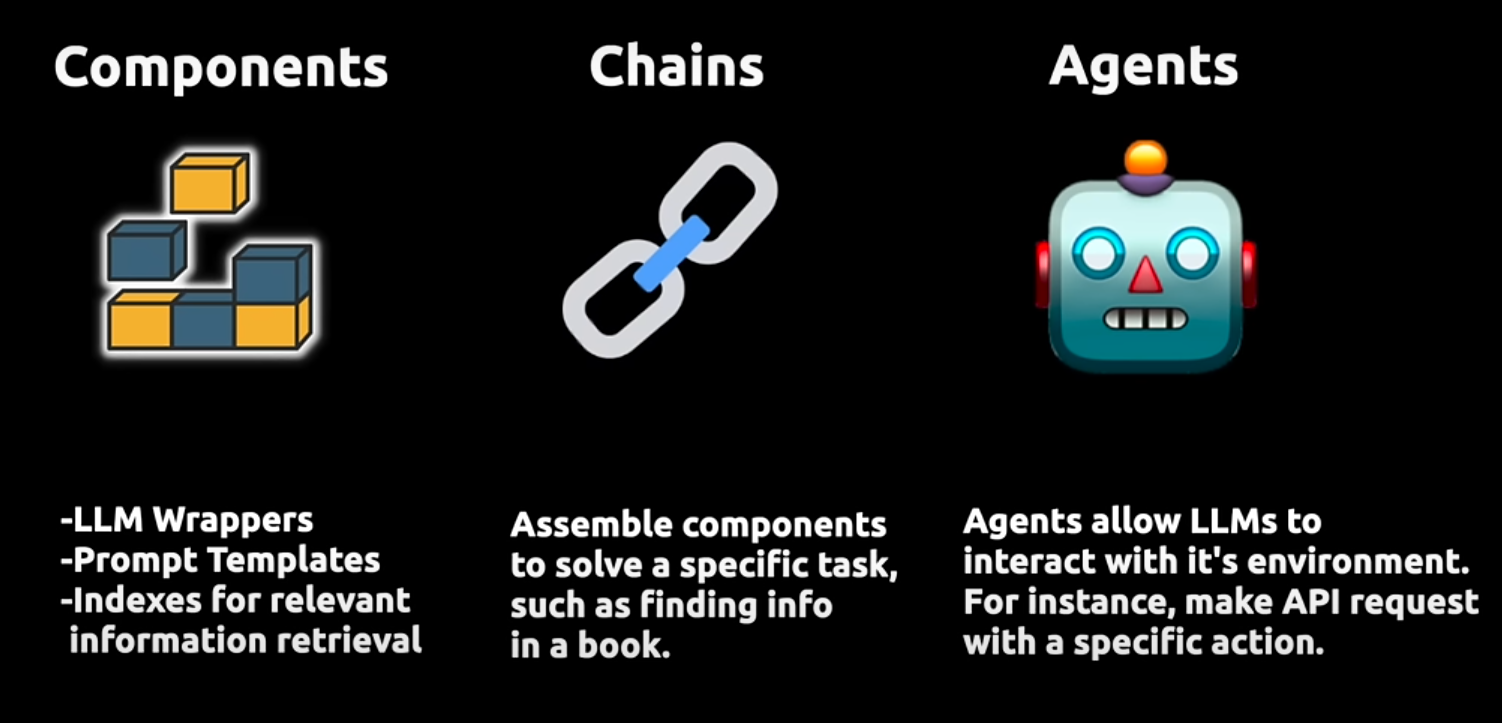
Lang chain is an open-source framework that helps the user to link multiple LLM models together to form a better application or it can provide various prompt templates rather than us trying to build the prompts ourselves. These prompt templates include some instructions to help us to perform our required tasks.
Apart from that LangChain also helps us to chain up multiple functions together. That is if you want to build an application where it retrieves data from a website and then preprocess it by embedding it and later it tries to send it to the LLM, this process can be combined and chained up together with the help of a concept called chains in the LangChain.
Not only that when we say we want to retrieve data from actual resources, LangChain also provides a module called indexes which helps us to either use our own data that is PDF files, or extract data from other external resources such as websites, YouTube transcripts, or any platform that we can extract data from. They also support VectorDB and other traditional databases like MongoDB, Pandas, etc.
When we say vector databases they store data in the numerical vector format, where each vector could represent different kinds of sentences, words, or phrases. (this is just in the case of textual data. but in reality, we can store any data in the form of vectors). Technically these are known as embeddings for the data we want to store.

LangChain also includes a memory component that helps the LLM to either remember the entire conversation or a specific part of the conversation which can help us to further improve the capabilities of LLM.
It also includes another groundbreaking component called agent which helps us build many real-time applications by allowing the applications to take actions based on the information at hand by using LLM as a reasoning engine. Let's understand this with a proper example, in a conversation chatbot when the chatbot fails to answer the user queries, based on its understanding of the conversation an LLM can transfer the conversation to a live human agent. Here transferring the conversation to a human agent is an action and it is taken based on the information that is present on the chat.
A traditional application using the LangChain will look like the image below

IMPLEMENTATION:
Let's dive deeper into the LangChain concept by implementing a practical application incorporating the key ideas we discussed. We’ll start with a basic application where the core functionality revolves around creating a chain that interacts with a large language model. This chain will take an input prompt, process it, and retrieve an output based on the input.
Additionally, we will implement a user interface using Streamlit, allowing us to create a simple, intuitive interface with easy-to-use interactive elements. This setup will enable users to input prompts and receive responses seamlessly, all within a well-designed application.
So we will begin with importing the required modules as shown in the picture below
Here's a breakdown of the imports:
1. OpenAI: This allows us to access the OpenAI LLM model.
2. PromptTemplate: Used to create a prompt template that we can pass into the LLM model.
3. StrOutputParser: Used to process the output from the LLM (Large Language Model) and return it as a plain string. This is particularly useful when you need a clean, human-readable response without additional formatting or metadata.
4. Streamlit: We'll use Streamlit to build a simple, user-friendly interface.
5. Load_dotenv: This helps us securely access API keys, like the OpenAI API key, without exposing them to users.
These components will form the foundation of our application, enabling us to interact with the LLM and present the results in a streamlined interface.
The next step is to load the API keys to our working environment
These API keys help us to access the required models with our specific ID. Everyone needs to create their own API keys to access the OpenAI model. The LangChain API key helps us track how the model is used, including when it's triggered, how long it takes to respond, and the resources it uses, like GPU. This tracking helps us monitor and optimize the model's performance.
There are many ways to create a prompt, this is one of the ways to create a prompt
In the code above, we're defining a system message that instructs the AI to assist the user based on their needs and to keep the response under 30 words. The user can input a question, which is captured by the `question` variable. This variable is then passed into the prompt template, and the AI generates a concise answer based on the user's input. The result is a clear and concise interaction between the user and the AI.
In the above code, we are creating a web page with the title "demochat." We also have a text box where the user can enter any question they want to ask the OpenAI model. The text entered by the user is stored in the
input_text variable for processing.
In the above code, we define the ChatOpenAI model using `gpt-3.5-turbo`. We also create a `StrOutputParser` to process the output from the large language model (LLM). Then, we construct a chain that works as follows:
1. Prompt: The chain starts by taking the prompt we defined earlier.
2. LLM: It then passes this prompt to the LLM (in this case, `gpt-3.5-turbo`).
3. Output Parsing: The output from the LLM is processed using the `StrOutputParser` we created.
Without this chain, we would need to manually write code for each of these steps—sending the prompt to the LLM and then parsing the output. The chain automates this process into a single line, making it easier and more efficient to use LangChain modules.
In the final part of the code:
1. Invoke the Chain: We invoke the chain by passing the user's input (`input_text`) into the prompt. The prompt template we defined earlier has a placeholder for the question, and the user’s input fills that spot.
2. Process and Display: The `input_text` is obtained from the text box where the user types their question. This text is passed into the prompt, creating a complete prompt ready to be processed by the chain.
3. Chain Workflow The filled prompt is automatically sent through the chain:
- First, it goes to the LLM (like `gpt-3.5-turbo`).
- Then, the output is processed by the `StrOutputParser`.
- Finally, the processed output is sent to the Streamlit interface using the `st.write()` command.
4. Display Result: The result of this entire process is displayed on the web page as the response to the user's question.
This code essentially ties everything together, making sure that once a user inputs a question, it flows through the system and returns a formatted answer back to the web interface.
This is a simple example of how we can use LangChain modules, such as prompt templates and chains. Keep in mind that this is just one way to use prompts—there are several other approaches. For example, you can use the PromptTemplate module in different ways or work with other modules to create forms. Additionally, you can deploy different LLM models besides OpenAI and create chains in various formats.
In future blogs, we’ll explore other topics like vector databases, agents, and indexing methods, discussing each one individually to make it easy to understand their applications.




Comments
Post a Comment